Automated Underwriting: What Yogi Berra and antidepressants can teach you about automated insurance underwriting
Yogi Berra once famously said, “Baseball is 90% mental. The other half is physical.”
There’s no question the math used in professional sports these days is different than it used to be. Rewind 20 years ago and you had baseball scouts relying on their “golden guts” to determine keen insights such as, “He’s got a major league ‘face’” or a “beautiful swing.”
Today, with the relentless advancement of data analytics permeating throughout professional sports, long-held determinants of success are quickly being exchanged for data-driven predictions.
Whether teams are trying to predict future performance to determine who to draft in this Thursday’s NFL draft, how much Mookie Betts is worth to the Red Sox over the next decade to determine his contract offer, or how likely it is Zion Williamson will injure himself to determine his load management, big data and machine learning are driving all of these decisions.
The reason these types of insights are now possible is a result of technological advancements that capture previously unseen and unimaginable amounts of data.

Companies like Seattle Sports Sciences use roughly 20 synchronized cameras in 4K ultra-high-definition video to evaluate soccer player’s skill and consistency. Who is passing or receiving with what frequency? What is the structure of the team’s defense at any given moment? It can even tell you how the ball spins and the rate of rotation.
In baseball, you’ll hear things like “WAR”, “ball flight”, and “exit velocity” used to describe aspects of a player’s ability.
This high-definition view of a player and the insights derived from the newly available data has paid major dividends.
Needless to say, the front offices of these sports franchises look a hell of a lot different than they did only a few years ago.
It’s a similar story in medicine…
The long-held medical tradition of “I’m sick…give me medicine to make me better” is giving way to “I’m going to do xyz so that I do not get sick.”
Preventative medicine is slowly but surely replacing prescription medicine.
As we’ve discussed before, why wait to get robbed to buy a home security system?
Even the futuristic use cases of modern medicine such as personalized or precision medicines are not as far off as once believed.
An easy way to think about this is as such…
Timmy, Becky, and Danny are all struggling with depression, go to the same doctor, and they are each prescribed the same antidepressant.
However, Timmy, Becky, and Danny all have very different chemical makeup and so the drug, which we will label as “yellow,” will likely have different effects on each of them. 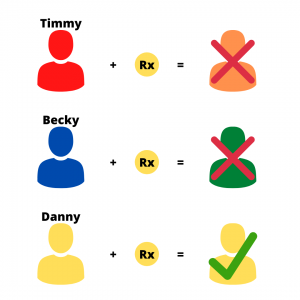
If Timmy is the color “red”, Becky is the color “blue”, and Danny is the color “yellow”, you will get three different reactions, or “colors”, to the medication.
Timmy will result in “orange”, Becky in “green”, and Danny will remain “yellow”.
If the goal is to match the color with color, you’re only batting .333. In baseball, that’s a Hall of Fame average…in medicine? Not so much…
In the future, however, this will not be the case. Instead, Timmy will first have his DNA analyzed, the doctor will note Timmy is “red”, and prescribe him a “red” antidepressant.
So instead of having one “yellow” one all-encompassing drug that works 33% of the time, we will have three drugs that work 100% of the time.
This is an oversimplification given there could be an infinite number of genetic combinations, but as the data set grows and the machines get smarter, we will make leaps and bounds towards this future.
Today, a cheek swab now produces 1.5GB of genomic data, and if that isn’t enough data, your watch will keep an eye on your heart rate, exercise habits, and sleep patterns.
What does this have to do with insurance?
While things like wearables and genomics are relevant to life and health insurance, there are plenty of similarities between what’s happening in sports, medicine, sports medicine, and insurance.
The “final answer data” as we like to call it is whatever answers are present when the customer/applicant presses “submit”.
Depending on the type of insurance, an application form could have anywhere from 20-150+ questions, so the carrier receives 20-150+ data points upon submission. Only by combining that data with traditional data sets can carriers make even a slightly accurate risk assessment as they attempt automated underwriting.
And even if you’re ahead of the game and work in satellite imagery for home, telematics for auto, or wearables for health policies, you’re still left with a low-resolution view of the applicant and their intent.
While this data improves the low-resolution view of an applicant, it’s still not a complete picture without behavioral analysis.
And with the transition to digital experiences and the invention of behavioral intelligence, it’s now possible to collect an exponentially higher amount of data to help with automated underwriting.
Now as with any new data set, having the data is valuable, sure, but collecting, analyzing, and drawing insights from it is where the true wealth lies.
What’s the point of having oil under your backyard if you can’t drill and sell it? (Maybe not the most timely metaphor as it might be cheaper today to keep it buried, but hopefully, you see my point!)
It took roughly 10 years after the genome was sequenced for insights to emerge. That’s because it takes time to find correlations between genes and real-world outcomes.
It’s no different from insurance. Let’s say you wanted to predict the likelihood that your first approved customer will submit a claim. Even if you had an infinite amount of data on that customer, you won’t have any claims data yet, therefore, the data is essentially meaningless.
It isn’t until customers start filing claims that we can begin to close the loop. And as more and more claims are filed, we’re able to retrain the predictive models over
and over, enabling them to get increasingly smarter and more predictive.
Just like our precision medicine example before, insurance policies are moving from a blanket ‘yellow medicine’ to more personalized medicine.
With that, population “averages” that have been used for years are quickly becoming obsolete.
Think of it this way, if you were making a trade for a baseball player but the only information you had was that the entire roster batted .260, how would you even begin determining the value of the individual player you are interested in?
You couldn’t.
Yet that is how most major insurance carriers are pricing today.
Now if you were able to split up the 9-man lineup into three groups, and then split them again, you would be left with a precise average of that particular player.
That’s now possible with solutions like Behavioral Intelligence.
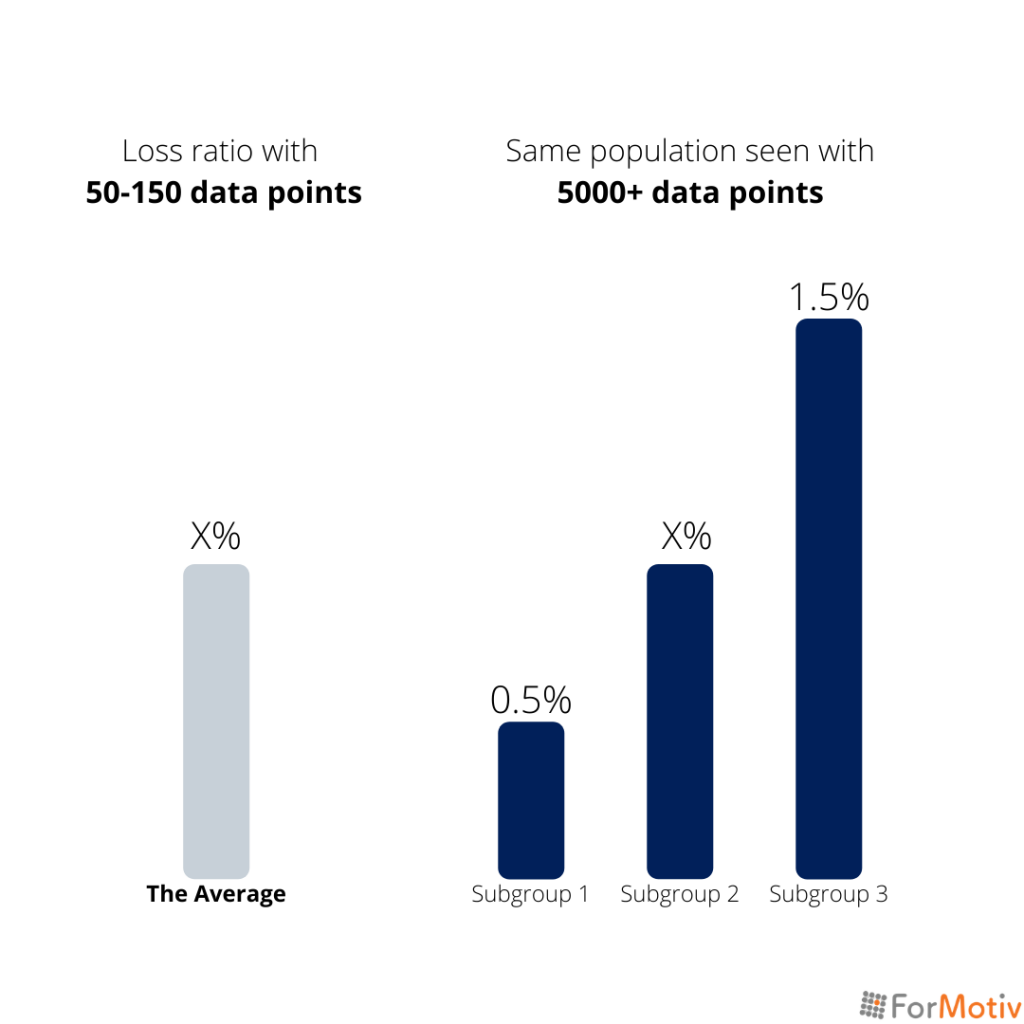
Certain populations or lineups to continue the analogy, that were initially viewed with the same average are starting to be viewed under advanced data microscopes like Behavioral Intelligence. What’s revealed are highly defined subgroups that can have up to a 3x difference in their losses. 🤯
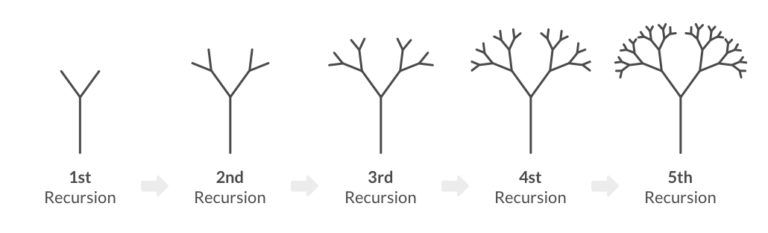
As the data continues to accumulate and mature, a recursive pattern emerges. Groups turn into sub-groups, those sub-groups turn into even more granular sub-groups, and so on. This allows underwriting algorithms to become more precise indefinitely.
As our friends at Lemonade put it, “Traditional insurers, with over a century of accumulated data each, still enjoy a data advantage over newcomers. But being digital natives, the neophytes have a structural advantage, and their penchant for growth and data is fast eroding the incumbents’ lead. It may be erased within the next 18–24 months.” (Note: they said that almost exactly 24 months ago…😳)
(Read more about Lemonade’s Loss Ratio and Behavioral Analytics strategy here)
Just like blood panels were replaced by genomic sequencing and “golden guts” replaced by high-def athlete tracking cameras, traditional insurance applications are currently being replaced by highly intelligent behavioral analysis or Behavioral Intelligence.
Being able to “see” people digitally, read their “digital body language”, and continuously put known outcomes back into the automated underwriting machine learning models, we’re left with a much clearer picture.
While this type of data extraction and analysis is new, initial correlations are already beginning to emerge. Predicting things like application abandonment, risky or fraudulent applicants, or figuring out who is most likely to file a claim are already showing promise, we’re still in the early innings of this game.
“Behavioral Intelligence is a lot like HD TV. I didn’t think I needed a clearer picture until I actually saw it – now there’s no way I can ever watch TV on an SD television again.”
As the data continues to accumulate and the flywheel continues to turn, the traditional way of underwriting will soon be obsolete and intelligent automated underwriting will take its rightful seat on the throne.