When was the last time you told a white lie?
To a spouse, to a friend, maybe a coworker. To protect someone’s feelings, to smooth over an awkward situation, to exaggerate enthusiasm you didn’t quite feel. Near-truths have become so normalized that most people don’t even register them as lies.
In the world of insurance, those same instincts — adjusted slightly, rationalized easily — are costing the industry $30 billion a year.
Not organized crime. Not fraud rings. Not synthetic identities or staged accidents. The majority of premium leakage in auto insurance comes from ordinary people making small, self-interested adjustments to their applications. Slightly understating their mileage. Listing a garaging address that’s more suburban than accurate. Quietly omitting a driver who had the bad luck of getting a speeding ticket last year.
The industry calls this “soft fraud.” And the reason it’s so difficult to address is that the people doing it don’t generally think of themselves as committing fraud at all.
The Numbers Are Getting Harder to Ignore
A 2021 survey found that 14% of Americans admitted to lying to their car insurer — nearly double the rate from the year before. That’s not a small sample anomaly. It’s a trend.
The generational breakdown is where it gets particularly interesting. Baby Boomers admitted to lying to their insurer at a rate of 8%. Generation X came in at 11%. Millennials at 15%. Gen Z at 18%.
There’s a correlation-versus-causation conversation to be had there, but it’s hard to ignore the obvious factor: the cohort most likely to lie to their insurer is the cohort that grew up applying for things through forms rather than through people. They’ve never sat across from an agent. They’ve never had a human being ask them directly whether they’ve had any recent accidents. They’ve interacted with an interface, adjusted some fields, and watched a number update in real time.
It’s a lot easier to tell a white lie to a dropdown menu than to a person looking at you.
Why the Industry Made This Easier
The insurance industry didn’t intend to make soft fraud more accessible. The goal was a better customer experience.
But consider what a real-time, frictionless digital auto application actually shows an applicant: every field they adjust updates their premium immediately. They can see, in dollars and cents, the difference between listing their teenage driver and not listing them. They can watch their monthly payment change as they adjust their annual mileage by 4,000 miles. There’s no agent asking a follow-up question. There’s no one who might catch an inconsistency.
The application was optimized for conversion. It happened to also be optimized for misrepresentation.
And here’s the thing — the incentive structure is entirely one-sided. The applicant who adjusts their answers gets a lower premium immediately. The consequence, if there is one, is abstract and distant: a potential coverage dispute at claim time, a policy rescission they might never experience, a theoretical impact on future insurability. Most people are not making a calculated fraud decision. They’re making a small, convenient adjustment and moving on with their day.
By the way, that $400–$700 that the average American family pays in excess annual premiums to cover others’ leakage? Nobody tells them about that when they’re filling out the application. The costs are visible only in one direction.
What is the cost of soft fraud in insurance?
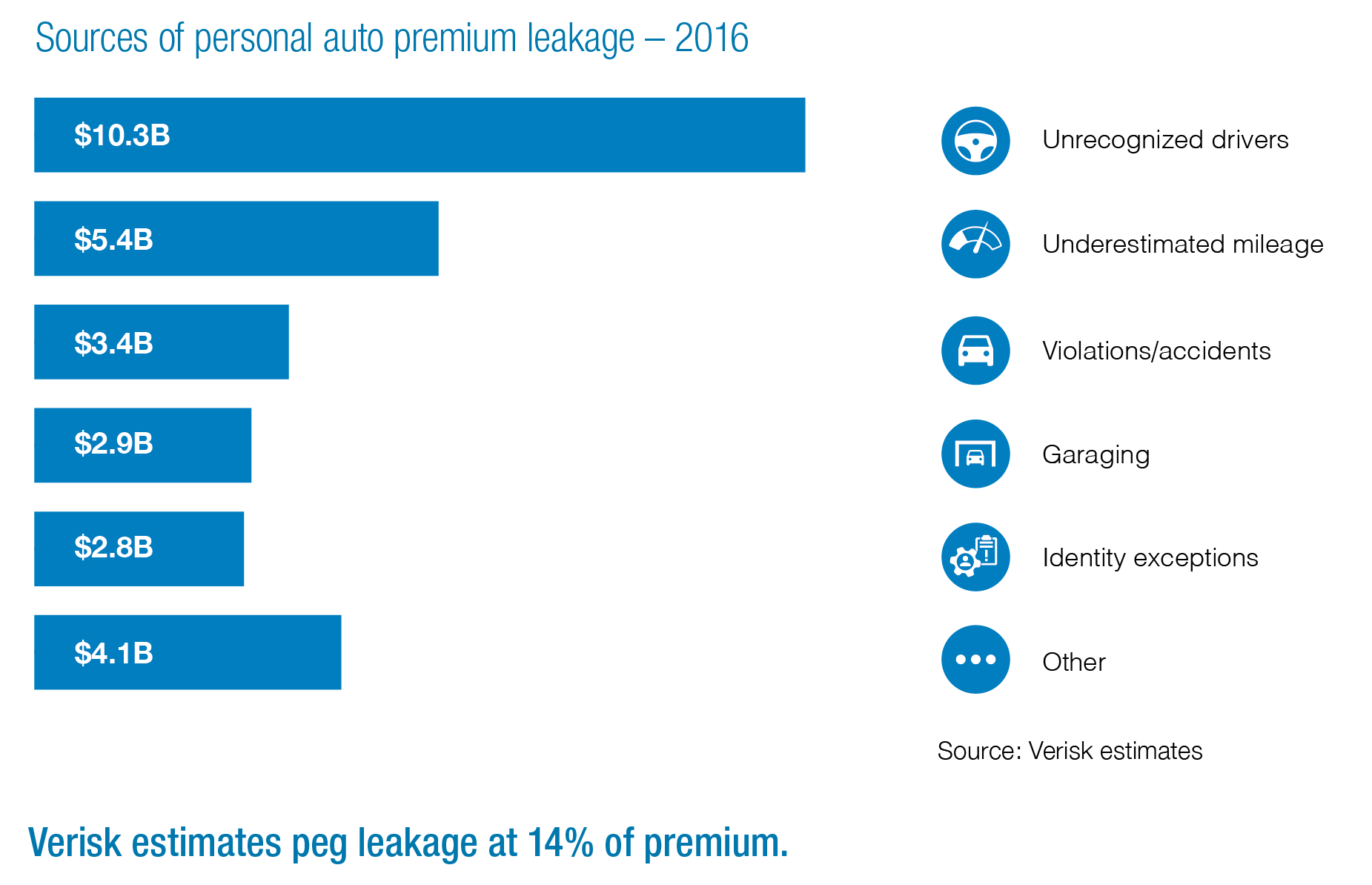
According to Verisk estimates, personal lines automobile insurers face at least $29 billion a year in premium leakage—missing or erroneous underwriting information that undermines their rating plans.
The “What” vs. “How” Framework
The insurance industry has historically been built around verifying the what — the submitted information. Did the applicant tell the truth about their driving record? Does their address match known data? Is the VIN registered where they say it is?
Third-party data providers — LexisNexis, Experian, Verisk, MVRs, CLUE reports — are built to answer those questions. They’re valuable, they’re widely used, and they do what they do well.
But soft fraud doesn’t necessarily live in the what. A garaging address can be technically accurate but practically misleading. A driver can be omitted without triggering any external flag. A mileage figure can be wrong with no record that would ever contradict it.
Soft fraud lives in the how. In how an applicant behaves while they’re entering their information. Whether they hesitated before answering a specific question. Whether they entered a field, watched the premium update, deleted their answer, and retyped something different. Whether they navigated back to a previous screen after answering a sensitive question.
That distinction matters because the how is observable in real time, during every application session, without asking the applicant a single additional question. The behavioral signal is generated automatically by the act of filling out the form.
A session where someone moved confidently through every field looks different from one where someone spent 45 seconds on the garaging address question before entering a zip code that doesn’t match the rest of their application. Those two sessions produce the same submitted data. They don’t produce the same behavioral trail.
What Behavioral Data Actually Catches
It’s important to be clear about what behavioral analytics does and doesn’t do.
It doesn’t identify fraud with certainty. Nothing does. And anyone who tells you otherwise is selling something.
What it does is surface behavioral patterns that correlate strongly with misrepresentation — and flag the specific applications where those patterns appear for closer review. The carrier still makes the decision. The behavioral signal is an input, not a verdict.
But it’s a meaningful input. The hesitation-then-edit pattern on a garaging address question shows up at significantly higher rates in applications that later surface misrepresentation in claims data. The driver removal followed by a premium review followed by submission — same thing. These aren’t random occurrences. They’re behavioral tells that exist in the session data and nowhere else.
We work with a majority of the top 10 P&C carriers, and what we hear consistently is that the applications flagged by behavioral scoring look different from the rest of the book — not universally, not with certainty, but at rates that are meaningful enough to warrant a different underwriting treatment.
That’s the goal: not a silver bullet, but an incremental signal that compounds over time across a book.
The Bigger Picture
Soft fraud persists because the system made it easy and the incentives pointed in one direction. Honest policyholders bear the cost in the form of higher premiums. Carriers bear it in deteriorating loss ratios that surface 18 months after the decisions that caused them.
The solution isn’t more friction on the application — friction is expensive, it penalizes honest customers, and it still doesn’t catch the applicant who will misrepresent their way through any process you put in front of them.
The solution is better visibility. Knowing not just what someone submitted, but how they behaved while submitting it. Understanding that the 86% of applicants who moved through straightforwardly are probably telling the truth — and that the 14% with behavioral patterns worth examining deserve a second look before a policy is issued.
That’s the shift. From catching soft fraud after the fact, when the claim arrives, to catching the behavioral signal that predicts it during the session.
Interested in learning more? Check this out: Behavioral Analytics for Insurance: The Complete Guide to Real-Time Risk Intelligence
Continue reading:
→ Back to the Premium Leakage Guide
→ Why Digital Insurance Created a $30 Billion Problem
→ How Behavioral Analytics Stops Premium Leakage Before It Starts
Curious how leading carriers are using behavioral intent data to address soft fraud? Let’s talk.